浙江私募大佬,一夜震驚矽谷
2025-01-19 01:33:52 來源:華商韜略

2024年冬天,杭州。
當西方還沉浸在聖誕節的狂歡中時,一位中國碼農,站在巨大的落地窗前,遠眺著窗外的京杭大運河。
幾分鐘後,他做了一件令矽谷震驚的事。
01 來自東方的神秘力量
“一種新的模式,讓整個山谷都嗡嗡作響!”
美國CNBC電視臺在報道這件事對矽谷的影響時,這樣評價道。
12月26日,杭州一家名為“深度求索”的中國初創公司,釋出了全新一代大模型:
DeepSeek-V3。
在多個基準測試中,DeepSeek-V3的效能均超越了其他開源模型,甚至與頂尖的閉源大模型GPT-4o不相上下。
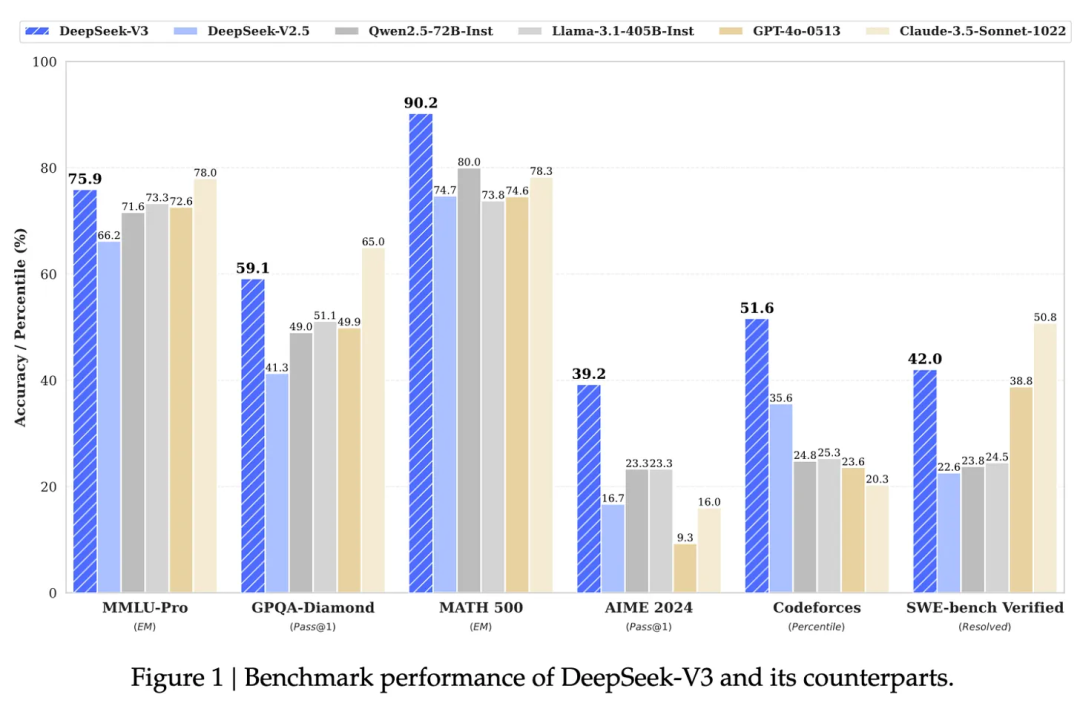
尤其在數學推理上,DeepSeek-V3更是遙遙領先。
令人驚訝的是,DeepSeek-V3在效能比肩GPT-4o的同時,研發卻只花了558萬美元,訓練成本不到後者的二十分之一。
這讓美國人徹底坐不住了。
在此之前,谷歌和Open AI花了幾年時間,耗資數億甚至數十億美元,呼叫了幾萬塊最先進的GPU,才幹成同樣的事情。
強烈的對比,讓美國人反思:大模型和算力,是否還值得投資?
很多矽谷大佬在紛紛點讚的同時,也體驗到中國科技帶來的苦澀:當美國人休息時,他們在奮力追上我們!
有意思的是,這件事與中國空軍六代機現身,幾乎前後腳發生。
不少美國人認為,這比六代機更像上世紀50年代,蘇聯搶先發射第一顆人造衛星的斯普特尼克時刻。
然而,真正讓美國矽谷感到震撼的,還不是DeepSeek-V3的高效能、低成本,而是中國人展現出的首創精神。
中國AI公司過去幾乎都在照搬矽谷,以致人們普遍認為:美國擅長從0到1的技術突破,而中國只擅長從1到100的應用落地。
DeepSeek-V3打破了這種成見,它以MLA、DeepSeekMoE等多項開創性技術,大幅提升了模型的效能和訓練效率。
美國人驚訝地發現,原來中國公司也可以作為創新貢獻者,在他們的遊戲之外,自定遊戲規則。這在過去是極其罕見的。
因為表現太過優越,DeepSeek在矽谷被譽為來自東方的神秘力量。
這股神秘的東方力量,令人稱奇的地方在於,它幕後的資方並不是騰訊、阿里這樣的網際網路巨頭,而是一家低調的私募基金——幻方量化。
目前,國內擁有萬卡GPU的企業不超過5家,幻方就是其中之一。
它在2023年成立子公司“深度求索”,開始DeepSeek大模型的研發,整個團隊只有139名成員,遠少於OpenAI的1200人。
執掌這支戰隊的,是一個叫梁文峰的80後,也是幻方量化的創始人。
02 當好奇心驅動了瘋狂
梁文峰和幻方的故事,始於2008年。
那一年,從浙大畢業、主修軟體工程的他,沒有像同齡人一樣,進入大廠當碼農,而是一個人跑到成都,蝸居在出租屋裡。
在那裡,梁文峰開始研究用計算機賺錢的各種路子。
幾番折騰下來,他決定下場做量化投資。但這個決定並不容易,畢竟當時量化在國內還是個新事物。
很多人並不相信,量化可以賺錢。
每當困難時,梁文峰總會想起量化投資之父西蒙斯的一句話:一定有辦法對價格建模。
在這個信念支撐下,梁文峰苦苦熬了兩年,終於柳暗花明。2010年,滬深300股指期貨推出,量化投資迎來了春天。
乘著這股東風,梁文峰和他的團隊大賺一筆,自營資金超過5億元。
也就是同一時期,隨著深度學習演算法的突破,人工智慧大爆發。早年在浙大就研究人工智慧的梁文峰,燃起雄雄鬥志。
2015年,他和浙大校友,共同創立了幻方量化。
幾個意氣風發的年輕人,試圖用數學和人工智慧,在中國打造一個像文藝復興那樣世界頂級的量化對沖基金。
僅僅一年後,他們就上線了第一筆由AI驅動的實盤交易,並在隨後,將所有交易策略都AI化。
新技術的加持,讓幻方量化旗下基金回報率,遠超同期滬深300指數。
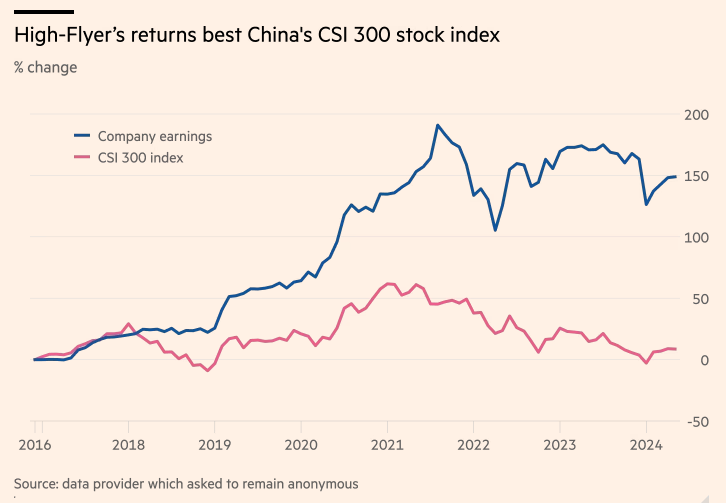
這推動幻方量化基金規模持續攀升,2021年一度超千億元大關,位列國內量化四大天王之一。
然而,基金規模膨脹的同時,梁文峰卻面臨一個棘手問題。
AI交易策略需要算力支援,尤其是,隨著模型引數的激增,對GPU算力的需求也在不斷增長。
如何破解這一難題?梁文峰的選擇是:堆算力!
從2019年開始,幻方量化大規模佈局AI算力。
當年就投資2億元,建成“螢火一號”AI算力叢集,搭載1100塊GPU算卡。而彼時的特斯拉,才剛剛提出Dojo超算概念。
幾個月後,當英偉達釋出最新A100晶片時,梁文峰再次搶跑,成為亞太地區第一批拿到此卡的人。
緊接著2021年,他又投資10億元,建成“螢火二號”,搭載1萬A100算卡,算力相當於76萬臺個人電腦。
其佔地面積,比10個籃球場還要大。
在AI大模型還沒有爆發的年代,梁文峰的舉動,讓很多人感到瘋狂。
一傢俬募基金囤這麼多算力,究竟意欲何為?甚至有媒體抱怨:幻方量化把A股散戶嚇壞了。
外界對幻方量化的想象,還停留在資本市場上。
但梁文峰的目光,早已望向星辰大海。
2017年,谷歌研究團隊在一篇開創性的論文中,首次提出Transformer架構。這是一種完全基於注意力機制的神經網路,它顛覆了過去的傳統演算法。
一家叫OpenAI的美國初創公司,基於新架構不斷訓練自己的大模型。最終在2022年以ChatGPT引爆AI大模型時代。
此後,全球網際網路巨頭,沿著OpenAI的路線推進,很少有人質疑。
但一群初生牛犢的年輕人,在梁文峰的帶領下,幹了一件極其瘋狂的事:他們試圖改進Transformer架構。
事實上,從2023年創立深度求索,進軍大模型的第一天起,梁文峰及其團隊對演算法框架的反思就開始了。
當別人陷入簡單模仿OpenAI的慣性中時,這群年輕人不走尋常路。
他們冒著失敗的風險,大膽嘗試了MLA(多頭潛在注意力機制)、DeepSeekMoE(混合專家模型)等多種開創性技術。
幾年前囤下的海量算力晶片,為他們的夢想,插上了翅膀。
最終,這群年輕人創造了歷史:DeepSeek-V3橫空出世,一夜震驚了矽谷。
03 “中國不可能永遠跟隨!”
對比中美科技產業,我們常常感嘆:
中國為什麼出不了像喬布斯、馬斯克、黃仁勳一樣偉大的企業家?
喬布斯生前只有一個目標:活著,就是為了改變世界。
黃仁勳早在青年時,就立下雄心壯志:要做不一樣的事,要徹底改變計算。
馬斯克更是瘋狂地喊出:要殖民火星,為人類尋找第二家園。
相比之下,中國企業家似乎把更多的目光,放在了賺錢和生存上,很少抬頭仰望星空,對創新的重視也不夠。
事實上,過去30年,我們已經習慣摩爾定律從天而降,躺在家裡18個月就會出來更好的硬體和軟體。
這使得我們在一輪又一輪的IT浪潮中,基本沒有參與到真正的技術創新裡。
但這種局面,在近幾年悄然改變,中國新生代企業家正以突破性創新,在西方的遊戲之外另起爐灶。
“中國也要逐步成為創新貢獻者,而不是一直搭便車。”梁文峰表示。
早在上大學時,梁文峰就篤定:AI一定會改變世界。畢業後,他在量化投資上,賺了足夠多的錢。
這使得他,有足夠的資本,聽從內心的聲音,去做自己喜歡的事情,而不是首先權衡利弊得失。
DeepSeek創立之初,就確立了核心使命:探索通用人工智慧的本質!
在中國AI界,還很少有企業敢提出如此瘋狂的目標。
於是,過去幾年,當很多大模型廠商忙著搶使用者,做商業化變現時,梁文峰卻苦哈哈搞起了看似不賺錢的基礎研究。
“創新不完全是商業驅動的,還需要好奇心和創造欲。”他說。
在梁文峰看來,中國企業在過去被商業驅動的慣性束縛了。他希望DeepSeek能擺脫這種束縛。
這樣的經營理念,在當下的中國企業界,顯得有點離經叛道。
曾經有不止一位業內人士表示:
梁文峰是中國AI界非常罕見的人,他擁有恐怖的學習能力,兼具強大的infra工程和模型研究能力,又能調動資源。
在內部員工看來,梁文峰則完全不像老闆,更像一個極客。
時至今日,他依舊延續著低調的作風,和公司其他研究員一樣,每天看論文,寫程式碼,參與小組討論。
這個低調的大佬,就連選人、用人的方式也跟主流格格不入。
當很多大模型公司熱衷於去海外挖人時,梁文峰卻反其道而行之,堅持從本土招人,並放出豪言:
“世界前50名頂尖人才可能不在中國,但也許我們能自己打造這樣的人。”
不僅沒有海外人才,也沒有行業大佬。梁文峰更喜歡沒有經驗的年輕人,因為他們不受條條框框的束縛。
在DeepSeek,選人的標準一直都是熱愛和好奇心。
事實上,這家初創公司並非外界傳言的,有一批高深莫測的奇才,而都是一些畢業才幾年的年輕人。
甚至,很多是北大、清華等Top高校還沒畢業的博四、博五實習生。
因為工作太前沿,這些年輕人在開展工作時,幾乎沒有參考資料。但也正是這種空白,讓他們敢於突破傳統。
比如,DeepSeek-V3最重要的創新之一MLA架構,就來自一個年輕人的突發奇想。
DeepSeek內部,也沒有上下級分工。
研究過程中,如果有想法,每個人都可以拉人討論,並隨時呼叫公司訓練叢集的卡,無需審批,不設上限。
這種看似鬆散的管理方式,極大地調動了所有人的好奇心和創造欲,讓DeepSeek-V3得以橫空出世。
在梁文峰身上,我們依稀看到了喬布斯、馬斯克、黃仁勳的影子。
“中國AI不可能永遠處在跟隨的位置!”
“真正的差距不是一年或兩年,而是原創與模仿之差。”
這兩句從梁文峰口中喊出的話,不僅事關AI產業,也是中國企業在跟隨、模仿了西方几十年後,不得不面對的突破方向。
低垂的果子都被摘完了,只有敢於突破,才能找到新的出路。
梁文峰並不孤單。
今天,從大疆無人機汪滔,到宇樹機器人王興興……一大批新生代企業家,正將中國科技產業帶向無人區。