中國算力的隱秘江湖:以前近10萬元的A100搶瘋了,現在很多卡都沒拆封
2025-01-24 01:31:45 來源:光錐智慧
文 白鴿
編輯 王一粟、蘇揚
要想富,先修路。
想要AI大模型能夠持續迭代升級,離不開底層算力基礎設施的搭建。自2022年ChatGPT爆發以來,算力市場也迎來了爆發式增長。
一方面,中國的科技巨頭們,為了搶佔未來AGI時代的門票,正在進行的算力“軍備競賽”,瘋狂囤積顯示卡資源的同時,也正在進行從千卡、萬卡再到十萬卡級別算力叢集的建設。
研究機構Omdia報告顯示,2024年位元組跳動訂購了約23萬片英偉達的晶片,成為英偉達採購數排名第二的客戶。
有報道稱,位元組跳動2025年的資本開支將達到1600億元,其中900億將用來購買AI算力。與位元組跳動同等規模的大廠,包括阿里、百度、中國電信等企業,也都在推進十萬卡級別的算力叢集建設。
而科技巨頭們瘋狂的算力基建行為,無疑也正在不斷將中國AI算力市場推向高潮。
但巨頭們瘋狂擴大算力規模的另一面,中國算力市場中卻有大量的算力資源被閒置,甚至開始出現“中國整體算力資源供過於求”的聲音。
“算力市場2023年非常火,做效能相對較低的A100的都賺到了錢,但2024年市場冷淡很多,很多卡都沒有拆封。不過各種因素疊加下,面向遊戲和消費市場的4090仍處於需求更多的狀態。”雲軸科技ZStack CTO王為對光錐智慧說道。
這兩年,算力生意是大模型浪潮中第一個掘到金的賽道,除了英偉達,也還有無數雲廠商、PaaS層算力最佳化服務商、甚至晶片掮客們都在前赴後繼。而這一輪算力需求的暴增,主要是由於AI大模型的迅猛發展所驅動起來的。
AI的需求就像一個抽水泵,將原來穩定多年的算力市場啟用,重新激起洶湧的浪花。
但現在,這個源頭動力發生了改變。AI大模型的發展,正逐漸從預訓練走向推理應用,也有越來越多的玩家開始選擇放棄超大模型的預訓練。比如日前,零一萬物創始人兼CEO李開復就公開表示,零一萬物不會停止預訓練,但不再追逐超大模型。
在李開復看來,如果要追求AGI,不斷訓練超大模型,也意味著需要投入更多GPU和資源,“還是我之前的判斷——當預訓練結果已經不如開源模型時,每個公司都不應該執著於預訓練。”
也正因此,作為曾經中國大模型創業公司的六小虎之一,零一萬物開始變陣,後續將押注在AI大模型推理應用市場上。
就在這樣一個需求和供給,都在快速變化的階段,市場的天平在不斷傾斜。
2024年,算力市場出現供需結構性失衡。未來算力基建是否還要持續,算力資源到底該銷往何處,新入局玩家們又該如何與巨頭競爭,成為一個個關鍵命題。
一場圍繞智慧算力市場的隱秘江湖,正徐徐拉開帷幕。

供需錯配:
低質量的擴張,碰上高質量需求
1997年,還很年輕的劉淼,加入了當時發展如日中天的IBM,這也使其一腳就邁入了計算行業。
20世紀中葉,IBM開發的大型主機被譽為“藍色巨人”,幾乎壟斷了全球的企業計算市場。
“當時IBM的幾臺大型主機,就能夠支撐起一家銀行在全國的核心業務系統的執行,這也讓我看到了計算讓業務系統加速的價值。”劉淼對光錐智慧說道。
也正是在IBM的經歷,為劉淼後續投身新一代智算埋下伏筆。
而在經歷了以CPU為代表的主機時代、雲端計算時代後,當前算力已進入到以GPU為主的智算時代,其整個計算正規化也發生了根本改變,畢竟如果沿用老的架構方案,就需要把大量資料透過CPU繞行再通往GPU,這就導致GPU的大算力和大頻寬被浪費。而GPU訓練和推理場景,也對高速互聯、線上儲存和隱私安全提出了更高的要求。
這也就催生了中國智慧算力產業鏈上下游的發展,尤其是以智算中心為主的基礎設施建設。
2022年底,ChatGPT的釋出正式開啟AI大模型時代,中國也隨之進入“百模大戰”階段。
彼時各家都希望能夠給大模型預訓練提供算力,而行業中也存在並不清楚最終算力需求在哪,以及誰來用的情況,“這一階段大家會優先買卡,做一種資源的囤積。”圖靈新智算聯合創始人兼研究院院長洪銳說道,這也是智算1.0時代。
隨著大模型訓練引數越來越大,最終發現真正算力資源消納方,集中到了做預訓練的玩家上。
“這一輪AI產業爆發的前期,就是希望透過在基礎模型預訓練上不斷擴大算力消耗,探索通往AGI(通用人工智慧)的道路。”洪銳說道。
公開資料顯示,ChatGPT的訓練引數已經達到了1750億、訓練資料45TB,每天生成45億字的內容,支撐其算力至少需要上萬顆英偉達的GPU A100,單次模型訓練成本超過1200萬美元。
另外,2024年多模態大模型猶如神仙打架,影片、圖片、語音等資料的訓練對算力提出了更高的需求。
公開資料顯示,OpenAI的Sora影片生成大模型訓練和推理所需要的算力需求分別達到了GPT-4的4.5倍和近400倍。中國銀河證券研究院的報告也顯示,Sora對算力需求呈指數級增長。
因此,自2023年開始,除各方勢力囤積顯示卡資源之外,為滿足更多算力需求,中國算力市場迎來爆發式增長,尤其是智算中心。
賽迪顧問人工智慧與大資料研究中心高階分析師白潤軒此前表示:“從2023年開始,各地政府加大了對智算中心的投資力度,推動了基礎設施的發展。”
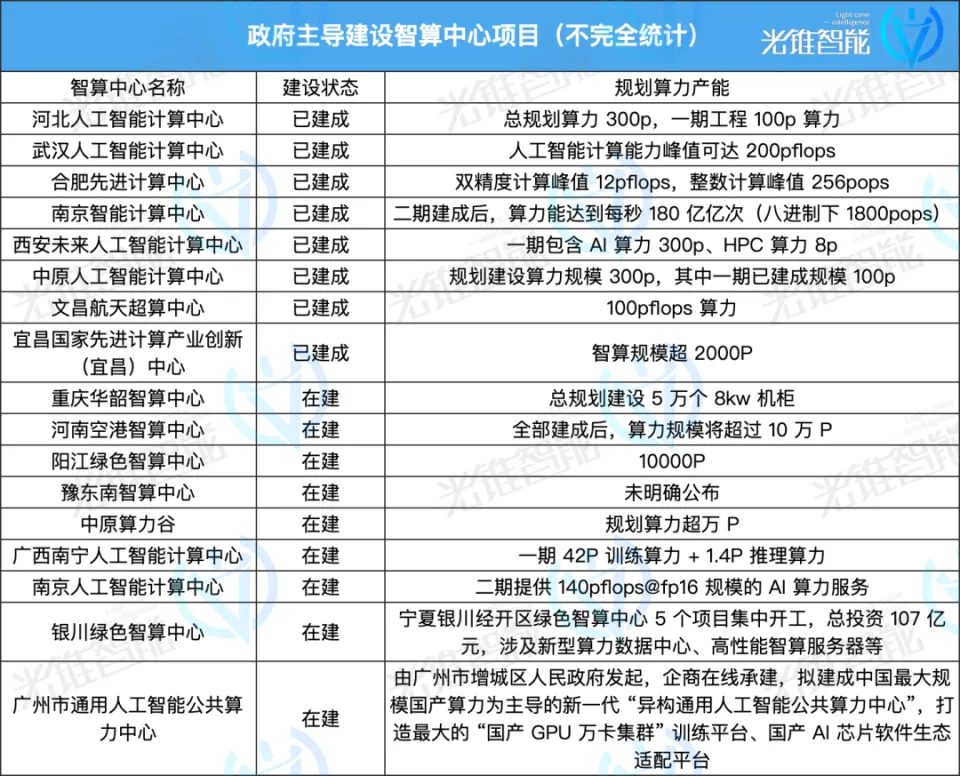
在市場和政策的雙重影響下,中國智算中心在短短一兩年時間如雨後春筍般快速建設起來。
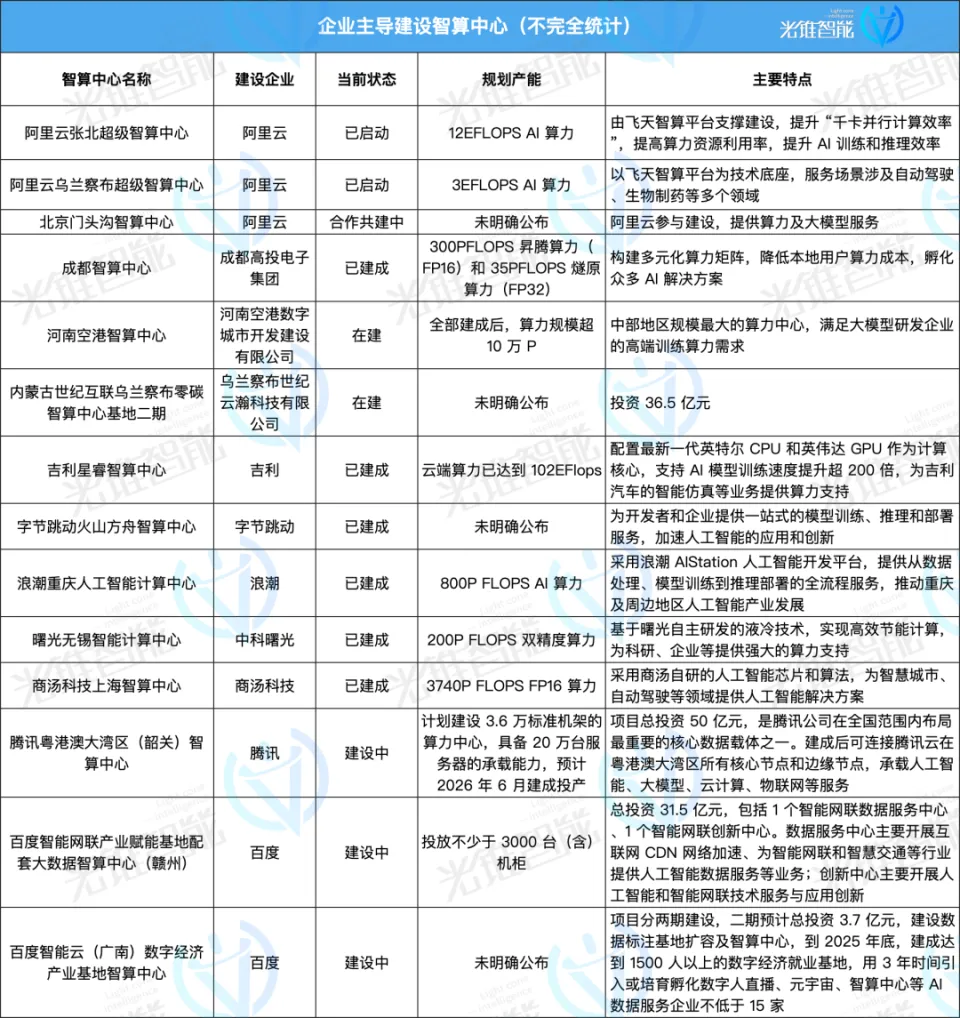
這其中既有政府主導建設專案,也有以阿里雲、百度智慧雲、商湯等企業為主開始投資建設的智算中心,更有一些跨界企業看到其中的機會從而邁入這一賽道。
同時,還有像圖靈新智算、趨境科技、矽基流動等創業公司進入到算力行業。
相關資料顯示,截至2024年上半年,國內已經建設和正在建設的智算中心超過250個,2024年上半年智算中心招投標相關事件791起,同比增長高達407.1%。
但是,智算中心的建設並非簡單的修橋鋪路,一是對技術和專業度的要求很高,二是建設和需求往往存在錯配,三是對持續的規劃不足。
在劉淼看來,智算中心其實是中國獨特的產物,某種程度上承擔了部分支援本地產業發展的社會使命,但不是純市場化的行為帶來一大問題,就是在長達12-24個月建設週期後,“建好了就閒置了,因為已經不能滿足2年後行業對算力需求了。”
從當前來看,中國算力市場資源在某些區域確實出現閒置。“中國算力市場現階段問題的根源,就在於太粗放了。”劉淼說道。
不過,市場不能簡單講是供需過剩,或者供需不足,實際上是算力供給與需求的錯配。即高質量的算力需求遠遠不足,但低質量的算力供給卻找不到太多的市場需求。畢竟,大模型預訓練玩家往往需要萬卡以上的算力資源池。
然而,中國算力市場上前期部分智算中心的規模,“可能只有幾十臺到一兩百臺,這對於當前基礎模型的預訓練來說是遠遠不夠的,但裝置選型是匹配的預訓練需求。”洪銳表示,站在預訓練角度,算力確實稀缺,但由於規模達不到而不能用的算力放在那裡就成了閒置。

大模型賽道分化算力需求悄然轉變
大模型市場的發展變化太快了。
原本在大模型預訓練階段,行業中玩家希望能夠透過不停的訓練來提升大模型效果,如果這一代不行,就花更多算力、更多資金去訓練下一代大模型。
“之前大模型賽道發展邏輯是這樣的,但到了2024年6月份左右,行業中能夠明顯感知到,大模型預訓練這件事已經到了投入產出的臨界點,投入巨量資源做預訓練,也可能達不到預期收益。”洪銳表示。
背後很重要的原因,在於“OpenAI技術演進的問題,GPT-3.5的能力很震撼,GPT-4的能力有提升,但是從2023年年中到2024年,整體的基座模型能力的升級達不到2023年的效果,再多的提升在CoT和Agent側。”王為如此說道。
基礎模型能力升級放緩的同時,預訓練的成本也非常高昂。
此前零一萬物創始人兼CEO李開復所言,一次預訓練成本約三四百萬美元。這對於大多數中小企業而言,無疑是一項高額成本投入,“創業公司的生存之道,是要考慮怎麼樣去善用每一塊錢,而不是弄更多GPU來燒。”
因此,隨著大模型引數越來越大,越來越多的企業無法承擔大模型訓練成本,只能基於已經訓練好的模型進行應用或者微調。“甚至可以說,當大模型引數達到一定程度後,大部分企業連微調能力都不具備。”洪銳說道。
有相關資料統計,2024年下半年,在透過備案的大模型中,有接近50%轉向了AI應用。
大模型從預訓練走向推理應用,無疑也帶來了算力市場需求的分化。洪銳認為:“大模型預訓練的計算中心和算力需求,以及推理應用的算力需求,其實已經是兩條賽道了。”
從大模型預訓練角度來說,其所需要的算力與模型引數量、訓練資料量成正比,算力叢集規模的整體要求是:百億引數用百卡,千億引數用千卡,萬億引數用萬卡。
另外,大模型預訓練的一個重要特徵,就是不能中斷,一旦中斷所有訓練都需要從CheckPoint重頭開始。
“去年至今,國內引進了大量智算裝置,但平均故障率卻在10%-20%左右,如此高的故障率導致大模型訓練每三小時就要斷一次。”劉淼說道,“一個千卡叢集,基本上20天就要斷一次。”
同時,為了支援人工智慧走向Agent時代甚至未來的通用人工智慧,需要不斷擴大算力叢集,從千卡叢集邁向萬卡叢集甚至十萬卡,“馬斯克是個牛人,規劃了孟菲斯十萬卡叢集,首個1.9萬卡,從安裝到點亮,只花了19天,其複雜程度要遠遠高出現有的專案。”劉淼說道。

馬斯克此前在X上宣佈啟用10萬卡規模的孟菲斯超級叢集
目前國內為了滿足更高引數大模型的訓練,也都在積極投建萬卡算力池,但“大家會發現,算力供應商的客戶其實都集中在頭部的幾個企業,且會要求這些企業簽訂長期的算力租賃協議,不管你是否真的需要這些算力。”中國電信大模型首席專家、大模型團隊負責人劉敬謙如此說道。
不過,洪銳認為;“未來全球真正能夠有實力做預訓練的玩家不超過50家,且智算叢集規模到了萬卡、十萬卡後,有能力做叢集運維故障排除和效能調優的玩家也會越來越少。”
現階段,已經有大量中小企業從大模型的預訓練轉向了AI推理應用,且“大量的AI推理應用,往往是短時間、短期間的潮汐式應用。”劉敬謙說道。但部署在實際終端場景中時,會需要大量伺服器進行並行網路計算,推理成本會驟然提升。
“原因是延遲比較高,大模型回答一個問題需要經過深層次推理思考,這段時間大模型一直在進行計算,這也意味著幾十秒內這臺機器的計算資源被獨佔。如果拓展至上百臺伺服器,則推理成本很難被覆蓋。”趨鏡科技CEO艾智遠對光錐智慧稱。
因此,相較於需要大規模算力的AI(大模型)訓練場景,AI推理對算力效能要求沒有AI訓練嚴苛,主要是滿足低功耗和實時處理的需求。“訓練集中於電力高地,推理則要靠近使用者。”華為公司副總裁、ISP與網際網路系統部總裁嶽坤說道,推理算力的延時要在5-10毫秒範圍內,並且需要高冗餘設計,實現“兩地三中心”建設。
以中國電信為例,其目前已在北京、上海、廣州、寧夏等地建立萬卡資源池,為了支援行業模型發展,也在浙江、江蘇等七個地方建立千卡資源池。同時,為了保證AI推理應用的低延時在10毫秒圈子裡,中國電信也在多地區建設邊端推理算力,逐漸形成全國“2+3+7”算力佈局。
2024年,被稱作AI應用落地元年,但實際上,AI推理應用市場並未如預期中迎來爆發。主要原因在於,“目前行業中尚未出現一款能夠在企業中大規模鋪開的應用,畢竟大模型本身技術能力還有缺陷,基礎模型不夠強,存在幻覺、隨機性等問題。”洪銳說道。
由於AI應用普遍尚未爆發,推理的算力增長也出現了停滯。不過,很多從業者依然樂觀——他們判斷,智慧算力仍會是“長期短缺”,隨著AI應用的逐漸滲透,推理算力需求的增長是個確定趨勢。
一位晶片企業人士對光錐智慧表示,AI推理其實是在不斷嘗試追求最佳解,Agent(智慧體)比普通的LLM(大語言模型)所消耗的Token更多,因為其不停地在進行觀察、規劃和執行,“o1是模型內部做嘗試,Agent是模型外部做嘗試。”
因此,“預估明年會有大量AI推理算力需求爆發出來。”劉敬謙說道,“我們也建立了大量的輕型智算叢集解決方案和整個邊端推理解決方案。”
王為也表示;“如果算力池中卡量不大的情況下,針對預訓練的叢集算力很難出租。推理市場所需要訓練卡量並不多,且整個市場還在穩定增長,中小網際網路企業需求量在持續增加。”
不過現階段,訓練算力仍佔據主流。據IDC、浪潮資訊聯合釋出的《2023-2024年中國人工智慧計算力發展評估報告》,2023年國內AI伺服器工作負載中訓練:推理的佔比約為6:4。
2024年8月,英偉達管理層在2024年二季度財報電話會中表示,過去四個季度中,推理算力佔英偉達資料中心收入約為40%。在未來,推理算力的收入將持續提升。12月25日,英偉達宣佈推出兩款為滿足推理大模型效能需要的GPU GB300和B300。
無疑,大模型從預訓練走向推理應用,帶動了算力市場需求的分化。從整個算力市場來說,當前智算中心還處於發展初期,基礎設施建設並不完善。因此,大型預訓練玩家或者大型企業,會更傾向於自己囤積顯示卡。而針對AI推理應用賽道,智算中心提供裝置租賃時,大部分中小客戶會更傾向於零租,且會更注重價效比。
未來,隨著AI應用滲透率不斷提升,推理算力消耗量還會持續提升。按照IDC預測結果,2027年推理算力在智慧算力大盤中的佔比甚至會超過70%。
而如何透過提升計算效率,來降低推理部署成本,則成為了AI推理應用算力市場發展的關鍵。

不盲目推卡
如何提升算力利用率?
整體來說,自2021年正式啟動“東數西算”建設以來,中國市場並不缺底層算力資源,甚至隨著大模型技術發展和算力需求的增長,算力市場中大量購買基建的熱潮,還會持續一兩年時間。
但這些底層算力資源卻有一個共性,即四處分散,且算力規模小。劉敬謙表示:“每個地方可能只有100臺或200臺左右算力,遠遠不能夠滿足大模型算力需求。”
另外,更為重要的是,當前算力的計算效率並不高。
有訊息顯示,即使是OpenAI,在GPT-4的訓練中,算力利用率也只有32%-36%,大模型訓練的算力有效利用率不足50%。“我國算力的利用率只有30%。”中國工程院院士鄔賀銓坦言。
原因在於,大模型訓練週期內,GPU卡並不能隨時實現高資源利用,在一些訓練任務比較小的階段,還會有資源閒置狀態。在模型部署階段,由於業務波動和需求預測不準確,許多伺服器往往也會處於待機或低負載狀態。
“雲端計算時代的CPU伺服器整體發展已經非常成熟,通用計算的雲服務可用性要求是99.5%~99.9%,但大規模GPU叢集非常難做到。”洪銳表示。
這背後,還在於GPU整體硬體發展以及整個軟體生態的不充足。軟體定義硬體,也正逐漸成為智慧算力時代發展的關鍵。
因此,在智慧算力江湖中,圍繞智慧算力基礎設施建設,整合社會算力閒置資源,並透過軟體演算法等方式提高算力計算效率,各類玩家憑藉自己的核心優勢入局,並圈地跑馬。

這些玩家大致可以分為三類:
一類是大型國資央企,比如中國電信,基於其央企身份能夠更好的滿足國資、央企的算力需求。
一方面,中國電信自己構建了千卡、萬卡和十萬卡算力資源池。另一方面,透過息壤·智算一體化平臺,中國電信也正在積極整合社會算力閒置資源,可實現跨服務商、跨地域、誇架構的統一管理,統一排程,提高算力資源的整體利用率。
“我們先做的是國資央企的智算排程平臺,透過將400多個社會不同閒置算力資源整合至同一個平臺,然後連線國資央企的算力需求,從而解決算力供需不平衡問題。”劉敬謙說道。
一類是以網際網路公司為主的雲廠商,包括阿里雲、百度智慧雲、火山引擎等,這些雲廠商在底層基礎設施架構上正積極從CPU雲轉型至GPU雲,並形成以GPU云為核心的全棧技術能力。
“下一個十年,計算正規化將從雲原生,進入到AI雲原生的新時代。”火山引擎總裁譚待此前說道,AI雲原生,將以GPU為核心重新來最佳化計算、儲存與網路架構,GPU可以直接訪問儲存和資料庫,來顯著的降低IO延遲。
從底層基礎設施來看,智算中心的建設往往並不是以單一品牌GPU顯示卡為主,更多的可能是英偉達+國產GPU顯示卡,甚至會存在透過CPU、GPU、FPGA(可程式設計晶片)、ASIC(為特定場景設計的晶片)等多種不同型別的計算單元協同工作的異構算力情況,以滿足不同場景下的計算需求,實現計算效力的最大化。
因此,雲廠商們也針對“多芯混訓”的能力,進行了重點升級。比如今年9月,百度智慧雲將百舸AI異構計算平臺全面升級至4.0版本,實現了在萬卡規模叢集上95%的多芯混合訓練效能。
而在底層基礎設施之上,影響大模型訓練和推理應用部署的,除了GPU顯示卡效能之外,還與網路、儲存產品、資料庫等軟體工具鏈平臺息息相關,而處理速度的提升,往往需要多個產品共同加速完成。
當然,除雲大廠外,還有一批中小云廠商以自己的差異化視角切入到算力行業中,如雲軸科技——基於平臺能力,做算力資源的排程和管理。
王為坦言,“之前GPU在業務系統架構中還只是附件,後續才逐漸成為單獨的類別。”
今年8月份,雲軸科技釋出了新一代AI Infra基礎設施ZStack AIOS平臺智塔,這一平臺主要以AI企業級應用為核心,從“算力排程、AI大模型訓推、AI應用服務開發”三個方向幫助企業客戶進行大模型新應用的落地部署。
“我們會透過平臺統計算力具體的使用情況、對算力進行運維,同時在GPU顯示卡有限的場景下,想要提升算力利用率,也會為客戶切分算力。”王為說道。
此外,在運營商場景中,算力的資源池比較多,“我們也會跟客戶進行合作,幫助其進行資源池的運營、計算、統一運營管理等。”王為表示。
另一類玩家,是基於演算法提升算力計算效率的創業公司,如圖靈新智算、趨鏡科技、矽基流動等。這些新玩家,綜合實力遠弱於雲大廠們,但透過單點技術突圍,也逐漸在行業中佔據一席之地。
“最開始我們是智算叢集生產製造服務商,到連線階段,則是算力運營服務商,未來成為智慧資料和應用服務商,這三個角色不斷演變。”劉淼說道,“所以我們定位是,新一代算力運營服務廠商。”
圖靈新智算未來希望,搭建獨立的整合算力閒置資源的平臺,能夠進行算力的排程、出租和服務。“我們打造一個資源平臺,將閒置算力接入平臺,類似於早期的淘寶平臺。”劉淼說道,閒置算力主要對接的是各地區智算中心。
與之相比,趨境科技、矽基流動等企業,更聚焦在AI推理應用市場中,並更注重以演算法的能力,來提升算力的效率,降低大模型推理應用的成本,只不過各家方案的切入點並不相同。
比如趨境科技為了解決大模型不可能三角,及效果、效率和成本之間的平衡,提出了全系統異構協同推理和針對AI推理應用的RAG(搜尋增強)場景,採用“以存換算”的方式釋放存力作為對於算力的補充兩大創新技術策略,將推理成本降低 10 倍,響應延遲降低 20 倍。
而面向未來,除了持續最佳化連線底層算力資源和上層應用的中間AI infra層外,“我們更希望的一種模式是,我們搭的是一個架子,房頂上的這些應用是由大家來開發,然後利用我們架子能夠更好的降低成本。”趨境科技創始人兼CEO艾智遠如此說道。
不難看出,趨境科技並不只是想做演算法最佳化解決方案供應商,還想做AI大模型落地應用服務商。
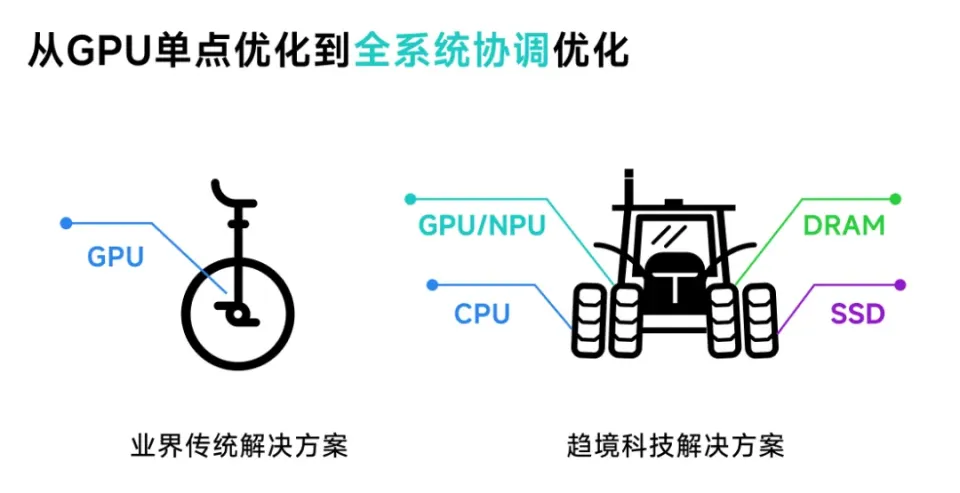
另外,當前行業中針對大模型算力最佳化方案,往往會優先考慮提升GPU的利用率。艾智遠表示,現階段對GPU的利用率已經達到50%以上,想要再提高GPU的利用率,難度非常大。
“GPU利用率還存在很大提升空間,但非常難,涉及到晶片、視訊記憶體、卡間互聯、多機通訊和軟體排程等技術,這並不是一家公司或一門技術能夠解決,而是需要整個產業鏈上下游共同推動。”洪銳也如此對光錐智慧說道。
洪銳認為,目前行業缺乏真正能夠從技術上將超大規模智算叢集組網運維起來的能力,同時軟體層並未發展成熟,“算力就在這,但如果軟體最佳化沒做好,或推理引擎和負載均衡等沒做好,對算力效能的影響也非常大。”
縱觀這三大類玩家,不管是中國電信等運營商,還是雲廠商們,亦或是新入局的玩家,各自切入算力市場的方式不盡相同,但都希望在這一場全球算力的盛宴中分得一杯羹。
事實上,現階段相比大模型服務,這的確也是確定性更強的生意。

算力租賃同質化
精細化、專業化運營服務為王
從賺錢的穩定度上,淘金者很難比得上賣水人。
AI大模型已經狂奔兩年,但整個產業鏈中,只有以英偉達為首的算力服務商真正賺到了錢,在收入和股市上都名利雙收。
而在2024年,算力的紅利在逐步從英偉達延伸到泛算力賽道上,伺服器廠商、雲廠商,甚至倒賣、租賃各種卡的玩家,也獲得了一定利潤回報。當然,利潤遠遠小於英偉達。
“2024年整體上沒虧錢,但是也沒賺到很多錢。”王為坦言,“AI(應用)現階段還沒有起量,跟AI相關量最大的還是算力層,算力應用營收相對較好。”
對於2025年的發展預期,王為也直言並未做好完全的預測,“明年真的有點不好說,但遠期來看,未來3年AI應用將會有很大的增量進展。”
但以各地智算中心的發展情況來看,卻鮮少能夠實現營收,基本目標都是覆蓋運營成本。
據智伯樂科技CEO嶽遠航表示,經測算後發現,一個智算中心縱使裝置出租率漲到60%,至少還要花上7年以上的時間才能回本。
目前智算中心對外主要以提供算力租賃為主要營收方式,但“裝置租賃非常同質化,真正缺失的是一種端到端的服務能力。”洪銳對光錐智慧說道。
所謂的端到端服務能力,即除硬體之外,智算中心還要能夠支援企業從大模型應用開發,到大模型的迭代升級,再到後續大模型部署的全棧式服務。而目前能夠真正實現這種端到端服務的廠商,相對比較少。
不過,從整體資料來看,中國智算服務市場發展前景越來越樂觀。據IDC最新發布《中國智算服務市場(2024上半年)跟蹤》報告顯示,2024年上半年中國智算服務整體市場同比增長79.6%,市場規模達到146.1億元人民幣。“智算服務市場以遠超預期的增速在高速成長。從智算服務的增長態勢來看,智算服務市場在未來五年內仍將保持高速成長。”IDC中國企業級研究部研究經理楊洋表示。
洪銳也表示,在經歷瘋狂囤積卡資源的智算1.0時代,到智算中心粗放擴張,供需失衡的智算2.0時代後,智算3.0時代的終局,一定是專業化、精細化運營的算力服務。
畢竟,當預訓練和推理分成兩個賽道後,AI推理應用市場會逐漸發展起來,技術棧也會逐漸成熟,服務能力逐漸完善,市場也將進一步整合零散閒置算力資源,實現算力利用率最大化。
不過,當前中國算力市場也仍面臨著巨大挑戰。在高階GPU晶片短缺的同時,“現在國內GPU市場過於碎片化,且各家GPU都有獨立的生態體系,整體的生態存在割裂。”王為如此說道,這也就導致國內整個GPU生態的適配成本非常高。
但就像劉淼所言,智算的20年長週期才剛剛開始,現在或許僅僅只是第一年。而在實現AGI這條道路上,也充滿著不確定性,這對於眾多玩家來說,無疑充滿著更多的機遇和挑戰。